
Most AI CV tools forget you — that's the whole problem
Everyone pastes their CV and a job description into AI and gets a polished, forgettable result. A career does not fit on two pages — so build an encyclopedia, let AI grill you for each role, and watch the CV improve.
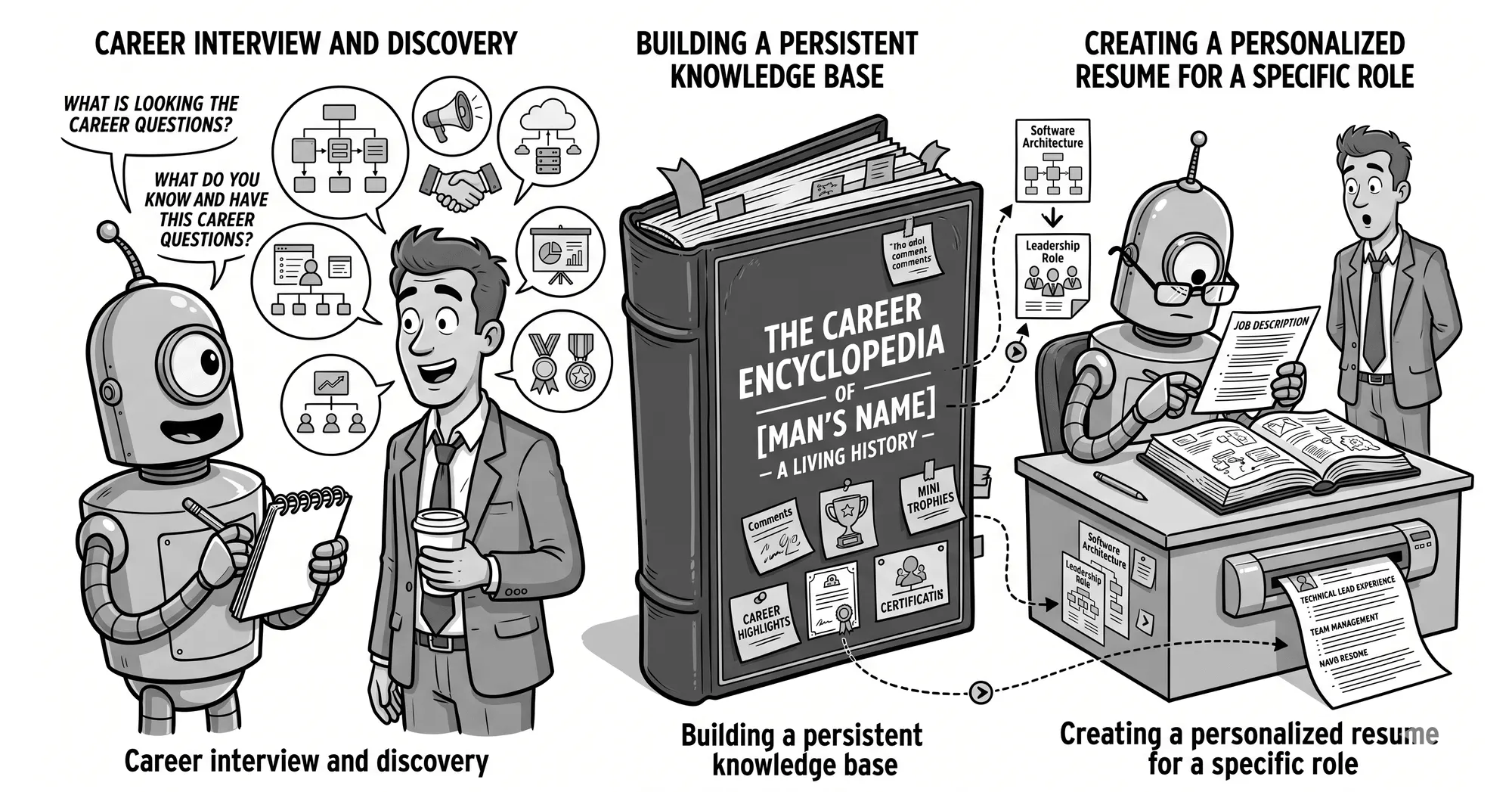
Here is the workflow almost everyone uses. You find a job you like. You copy the description. You paste it into ChatGPT or Claude with “tailor my CV for this role,” attach your existing CV, and forty seconds later you have a clean, plausible, perfectly forgettable document.
The output is fine. The approach is a dead end.
Not because the model is bad at writing CVs — it is genuinely good at it. The problem is the input. You hand it two pages, and a twenty-year career does not fit on two pages. It never did. So the model dutifully reshuffles a lossy summary of you, and then it forgets you the moment the tab closes — starting from zero the next time, working from the same stale document you’ve been recycling for three years.
So here is the alternative. Stop pretending your career fits on a page. Have AI build a living encyclopedia of everything you’ve ever done, let it grill you in a focused interview for every role you target, and update that record at every application. Feed that to the model instead of the two-pager, and the CV it writes is drawn from your whole career — not the flattened version it used to start from.
That’s the part nobody fixes. So I tried to.
The thing your CV never captured
Every CV is ruthlessly trimmed — one or two pages, reverse-chronological, twenty years of work flattened into bullet points. It has to be. And the stuff that gets trimmed is often exactly what a specific employer is looking for.
You did pre-sales at that one job, but it wasn’t your title, so it never made the CV. You provisioned the cloud infrastructure yourself before the company could afford a platform team. You ran a side project that quietly hit a million users. You led a migration that everyone has forgotten because it worked. None of it is on the page. So when an AI tailors your CV from that page, it can only reshuffle what’s already there. It cannot surface what was never written down.
A one-shot tool will never find these things, because it never asks. It takes your summary at face value and optimizes the wording.
The bottleneck was never the writing. It was the remembering.
A memory that compounds
So I built AI Career Coach, a Claude Code plugin, around a single inversion: instead of a model that forgets you after every session, give it one that accumulates you.
The core of the system is a career encyclopedia — a structured, living document that holds everything known about your professional history. Roles, achievements, technologies, honest proficiency levels, the stories you actually tell, what you want next. It is the single source of truth, and every other part of the plugin reads from it and writes back to it.
The “writes back” is the whole point.
When you analyze a job with /jd, the plugin doesn’t just score it. It conducts a short gap interview — one question at a time, with pre-baked answer options — aimed at the specific role in front of you. A fintech role asks about your fintech-adjacent work. A platform role digs into the infrastructure you’ve touched. And those interviews are where the buried experience comes out: “oh right, I did own that vendor relationship.” Every one of those discoveries gets written back into the encyclopedia.
So the asset grows:
- Job #1. You paste your CV, answer ten questions. The encyclopedia has the basics.
- Job #5. Gap interviews have surfaced pre-sales experience you forgot, a side project with real scale, and the fact that you ran your own cloud bills for two years.
- Job #15. The model knows your career deeply enough to frame you as a “builder who brings order to complexity” for a startup, or a “transformation leader” for an enterprise — each version truthful, each precisely targeted, each drawing on details that never appeared on any single CV.
CV #15 is dramatically better than CV #1, and not because the writing improved. Because the context did. The encyclopedia is the compounding asset; every conversation makes it richer. I’ve now run it against nineteen real director and head-of-engineering roles, and the difference between the early outputs and the recent ones is not subtle.
It also tells you to pass
A tool optimized for output wants you to apply to everything — more applications, more usage, more engagement. That incentive is exactly backwards.
/jd scores a role against the dimensions you care about — hard skills, domain, leadership scope, culture, trajectory — and then gives an honest verdict: strong match, worth applying, stretch, or pass. When the answer is pass, it says pass. Your time is the scarce resource, not the supply of open roles. An AI that talks you out of a bad application is doing more for your career than one that cheerfully generates the cover letter.
And when it is worth applying, /cv doesn’t just reshuffle bullets. It picks a frame for the role — Builder, Enterprise Leader, Product Leader, Transformation Leader, Startup CTO — and tailors the headline, summary, and emphasis to match, then outputs markdown, print-ready HTML, and a PDF. Same truthful history, different lens. The way you’d present yourself differently in two interviews on the same afternoon.
The rule underneath all of it: never fabricate, but represent strategically. Frame oversight as oversight, not hands-on depth. Put the truth in its most favorable light. The CV’s job is to get you past the screen so you can prove the rest in person — not to lie.
Memory, not a better model
Strip away the job-search specifics and what’s left is the pattern I keep running into everywhere I use these tools seriously.
The leap in usefulness doesn’t come from a smarter model. It comes from giving the model persistent, structured context that survives across sessions. A stateless chat is a brilliant intern with no memory — impressive in the moment, useless for anything that compounds. The moment you give it a durable place to accumulate what it learns about a domain, the same model becomes something else entirely: a collaborator that gets sharper every time you show up.
A career is just a clean example because the value is so legible. But the shape generalizes to almost any long-running work you’d want an agent to help with. The teams getting outsized results from AI right now are not the ones with access to a better model. They’re the ones who figured out where the memory lives.
If you want to try it, it’s open source and MIT-licensed. Add the marketplace and install:
claude plugin marketplace add max-favilli/ai-career-coach
claude plugin install ai-career-coachThen, in a fresh folder for your job search, four commands run the whole loop:
/setup— a one-time interview that builds your encyclopedia. Paste an existing CV or LinkedIn export to bootstrap it in minutes, then optionally define the dimensions you want roles scored on./jd— paste a job description. It scores the role, gives you an apply / stretch / pass call, runs the gap interview, and quietly writes whatever it learns back into the encyclopedia./cv— for a role worth applying to, it picks a frame and generates the tailored CV as markdown, styled HTML, and PDF./add-to-encyclopedia— drop in anything new anytime — an old CV, a side project, a win you forgot — outside the job-search flow.
The first run takes about ten minutes. After that, every application makes the next one sharper.
Your next CV will be roughly as good as your last one. The one after a year of this will be built by something that actually knows you.
(This post was written with Claude, which by now knows more about my career than my CV ever did — because I stopped making it start from scratch.)
Discussion
This post isn’t on Substack or LinkedIn yet — if you have thoughts, email is the best way to reach me.